




 뉴스
뉴스
 리서치
리서치
 마켓정보
마켓정보
 라운지
라운지
 커뮤니티
커뮤니티
 매체소개
매체소개
 고객센터
고객센터






















 0
0



인공지능 분야의 핵심 과제로 부상한 ‘과도 학습(Catastrophic Overtraining)’ 문제가 다시금 주목받고 있다. 최근 카네기멜런대, 스탠퍼드대, 하버드대, 프린스턴대 등 세계적 명문 대학 소속 연구진이 공동 발표한 연구에 따르면, 대형 언어모델(LLM)이 더 많은 데이터로 사전학습될수록 오히려 성능이 저하될 수 있다는 충격적인 결과가 확인됐다. 이는 지금까지 LLM 개발의 기본 원칙으로 여겨져온 ‘데이터가 많을수록 좋다’는 가정을 정면으로 반박하는 분석으로 평가된다.
해당 연구는 “과도하게 학습된 언어모델은 미세조정이 더 어렵다(Overtrained Language Models Are Harder to Fine-Tune)”라는 제목으로 공개됐으며, 야곱 미첼 스프링거를 비롯한 총 8인의 저자가 공동 집필했다. 연구진은 특히 AI2의 오픈소스 모델 OLMo-1B를 사례로 들어, 학습 토큰 수를 2.3조 개와 3조 개로 나눈 두 버전을 비교 분석했다. 놀랍게도 더 많이 학습된 3T 모델이 정식 미세조정 후 성능이 떨어졌고, 여러 표준 벤치마크에서 최대 3%의 성능 저하가 발생했다. 연구진은 이를 일회성이 아닌 반복 가능한 구조적 문제로 규정하며 ‘과도 학습’의 개념을 제시했다.
이 같은 성능 악화는 단지 수치상의 편차가 아니라, 모델이 학습 후 극단적으로 민감해지는 체계적 변화 때문으로 분석됐다. 연구에서는 이를 ‘점진적 민감도(progressive sensitivity)’라고 명명했으며, 이로 인해 모델은 작은 미세조정이나 노이즈에도 쉽게 성능이 약화되는 취약성을 드러냈다. 기존에 습득한 능력을 후속훈련 과정에서 잊는, 이른바 ‘망각’ 현상이 두드러졌다는 것이다.
특히 문제는 ‘한계점(inflection point)’ 이후 급격히 나타났다. 연구진은 사전학습이 일정량을 초과할 경우, 이후 미세조정 효과가 급속히 감소하거나 부정적으로 전환된다고 분석했다. OLMo-1B의 경우, 이 임계치는 약 2.5조 토큰으로 확인되었으며, 이후 학습은 오히려 성능 전반을 해쳤다. 실험은 앤스로픽-HH, TULU 등 다양한 데이터셋과 LLaVA 기반의 멀티모달 미세조정 등에서도 일관된 결과를 보였으며, 실험실 환경 뿐 아니라 실제 적용 사례에서도 성능 하락이 반복적으로 관찰됐다.
연구진은 단순한 실험 외에도 선형 신경망 기반 이론모델을 직접 구축해 수학적으로도 이 현상이 불가피하게 발생함을 입증했다. 학습량이 일정 조건 이상 지속될 경우 점진적 민감도가 상승하고, 이는 모델 성능을 저하시킨다는 것이다.
이번 연구는 산업계에도 적지 않은 파장을 예고한다. 특히 중소기업이나 스타트업 입장에서, 오픈소스 대형 언어모델을 활용해 맞춤형 AI를 개발하려는 경우, 모델의 사전학습량이 무조건 많을수록 좋다는 판단은 치명적일 수 있다. 연구진은 “오히려 적절한 토큰 수로 훈련된 경량형 모델을 기반으로 미세조정을 시도하는 것이 더 안정적이고 실용적인 결과를 제공할 수 있다”고 조언했다. 일부 정규화 기법이나 학습률 조정으로 증상을 늦출 수는 있지만, 근본적인 해결책은 아니라는 한계도 분명히 했다.
이번 분석은 향후 AI 훈련 전략의 패러다임 전환을 촉진할 것으로 보인다. 지금까지는 대규모 데이터 확보와 훈련이 AI 경쟁력의 핵심으로 인식돼 왔지만, 이제는 ‘얼마나 오래’보다 ‘언제 멈추느냐’가 더 중요해졌다. 리소스를 효율적으로 배분하고 후속 미세조정 가능성까지 고려한 종합적 판단이 요구되는 시점이다.
아직 해결되지 않은 과제도 많다. 사전학습 중 과도 학습을 유발하는 핵심 요인을 훈련 알고리즘, 목적 함수, 데이터 분포 등에서 규명하는 후속 연구가 이어질 전망이다. 다만 이번 결과는 LLM 분야의 ‘무조건적 확장’ 전략에 경고를 던진 이정표라는 점에서 업계 전반에 깊은 시사점을 제공하고 있다.





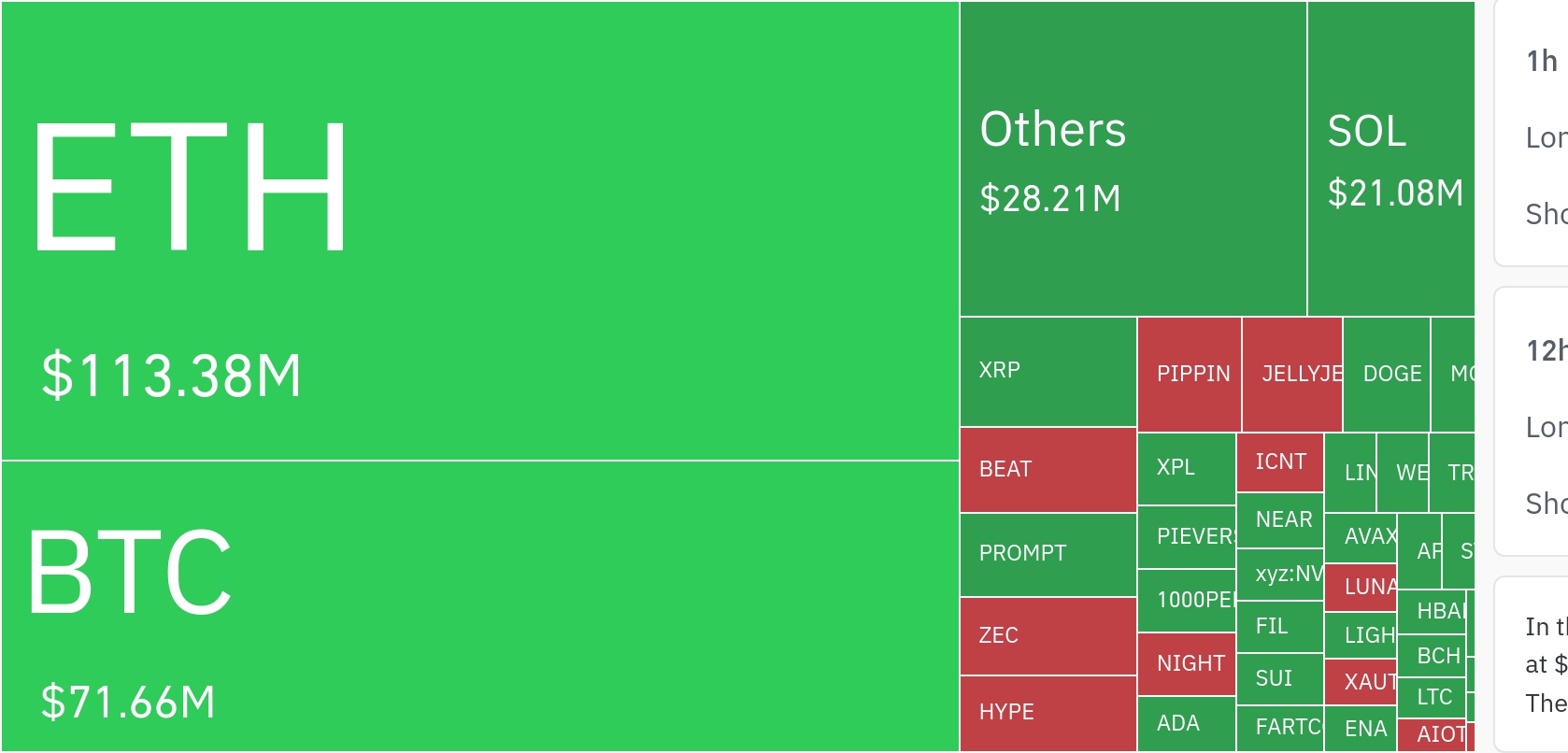


![[저녁 시세브리핑] 암호화폐 시장 하락세… 비트코인 90,368달러, 이더리움 3,094달러](https://f1.tokenpost.kr/2025/12/5npgd6waqa.jpg)











![[Episode 12] IXO™2024 참여하고, 2억원 상당 에어드랍 받자!](https://f1.tokenpost.kr/2024/03/bk2tc5rpf6.png)
![[Episode 11] 코인이지(CoinEasy) 에어드랍](https://f1.tokenpost.kr/2024/02/g0nu4cmps6.png)
![[Episode 8] Alaya 커뮤니티 입장하고, $AGT 받자!](https://f1.tokenpost.kr/2023/10/0evqvn0brd.png)
![[토큰포스트] 기사 퀴즈 490회차](https://f1.tokenpost.kr/2025/12/hinl1077xr.jpeg)
![[토큰포스트] 기사 퀴즈 489회차](https://f1.tokenpost.kr/2025/12/6rb73ok3c3.jpeg)
![[토큰포스트] 기사 퀴즈 488회차](https://f1.tokenpost.kr/2025/12/us5um50ulw.jpg)
![[토큰포스트] 기사 퀴즈 487회차](https://f1.tokenpost.kr/2025/12/685fnpghrs.jpeg)
























